With the latest UniProt release 2015_12, we are introducing new genome annotation track files in both BED and bigBed formats that will allow you to view human UniProtKB sequence feature annotations such as domains, sites and post-translational modifications as genome browser tracks! This initial beta release of the UniProt genome annotation tracks resource contains sequence annotations for human only but it will be followed by additional species in the future.
As well as the standard tracks provided by the UCSC and Ensembl genome browsers, both browsers allow users to upload additional tracks that annotate the genome further to help understand its architecture . Genome browser tracks also allow users to analyze their own sequencing data against the reference genome data and genome annotations. You will now be able to upload files from UniProt to genome browsers to be able to easily compare UniProtKB protein features with other genomic information and also with your own sequencing data if available, bridging the protein and gene visually.
Each species represented (currently only human) within the genome annotation tracks resource will have its sequence annotations defined with the BED and bigBed formats.

For example the human active site BED file is called: UP000005640_9606_act_site.bed. BigBed formatted files have a .bb extension. You will see two directories on the FTP site for each species (currently only human), one directory for the BED files and a track hub directory that can be used to add all UniProtKB sequence annotations for a species to a genome browser.

All UniProt annotation tracks can be added in one single step by adding the UniProt species track hub. Simply copy the URL for the species hub.txt file and follow the genome browser instructions on how to add a track hub.

Adding a UniProt species track hub to the Ensembl genome browser.

UniProt FGFR2 features uploaded using a track hub visualized in the Ensembl genome browser.

Adding a track hub in the UCSC genome browser.
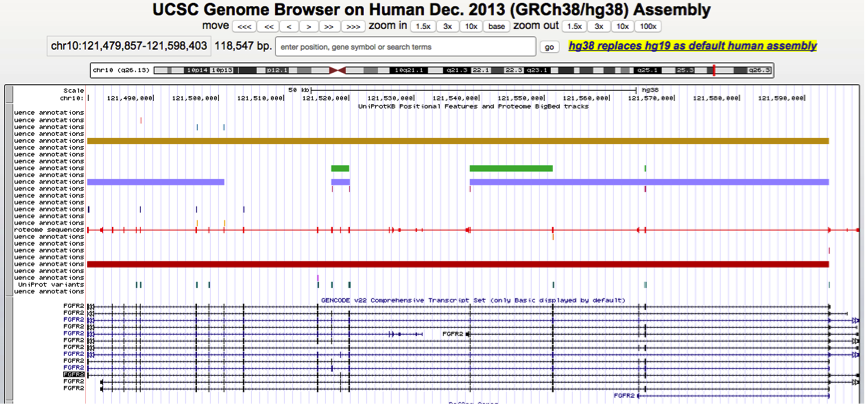
UniProt FGFR2 features uploaded using a track hub visualized in the UCSC genome browser.
In order to add specific feature annotation tracks on a genome browser like Ensembl, simply copy the URL to the file and follow the instructions on how to add custom tracks in the Ensembl genome browser or UCSC genome browser. Individual bigBed files can be added as tracks to a genome browser by utilizing the track definitions provided in the species tracks.txt (UP000005640_9606_tracks.txt) file.

Adding custom tracks to the Ensembl genome browser

Adding custom tracks
or track definitions to UCSC genome browser.

UniProt active site annotation track in the Ensembl genome browser.
We welcome your
feedback on this new resource!












