UniProt is brought to you by a large team of dedicated scientists who have worked for over 20 years to produce a comprehensive view of protein sequence and biology. This work would not be possible without the generous support of the National Institutes of Health (NIH), the European Molecular Biology Laboratory (EMBL), and the Swiss Secretariat for Education Research and Innovation (SERI). Throughout this period we have been asked regularly by our funders to describe the impact that their support has in both scientific and economic terms. To do this we have developed a number of scientific impact metrics and indicators that are normally only ever seen by a small number of people; we will share some of these scientific impact metrics with you in this blog, while those interested in learning more about the economic impact of resources like UniProt may wish to consult the 2021 report on “The value and impact of EMBL-EBI managed data resources” by Charles Beagrie and associates. We hope that you will be impressed by the numbers, that they will encourage you to continue to support UniProt, and that they may inspire you to apply some of these tools and techniques we describe to study the impact and benefits of your own work.
All the tools that we use to calculate impact metrics are freely available, and this work should be relatively easy to replicate for your own data. We would like to give a special thanks to the teams at PubMed and Europe Pubmed Central (Europe PMC) for all their hard work in developing a series of brilliant tools to organize and index the scientific literature - thank you! Many of the impact metrics described here are widely used by other biomedical data repositories and knowledgebases (according to a recent report from the NIH Office of Data Science Strategy). In what follows we provide a gentle introduction to how we measure them.
Website metrics
UniProt’s website acts as its shop window, the main point of access to the knowledge that we have gathered and organised over the years. We have aimed to make the website simple to use and yet powerful, as well as making all data freely available for download. The key tools for monitoring our website are Google Analytics and web server log analysis.
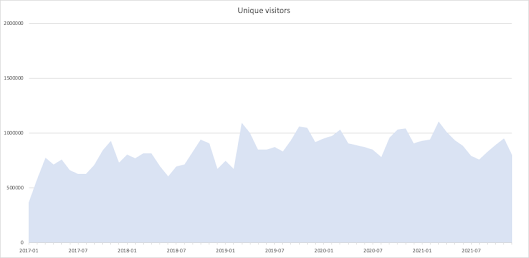
Figure 1. Google analytics analysis of the UniProt website.
Web statistics are quite challenging to interpret. In classical web server log analysis, the statistics on unique users are based on the number of unique IP addresses counted, but a single person may have multiple devices, each with a unique IP address, while institutions with thousands of users may show only a single IP address. Google Analytics and similar services use cookies to count interactive users and therefore overestimate actual users by the number of devices they use. The increasing usage of cloud computing also leads to an overestimation of user numbers. So these figures should only be interpreted as indicative of the scale of the number of users and general trends in usage over time. All web analytics software also change how certain numbers are calculated from time to time, which can lead to increases or decreases in user numbers that are related to methodology rather than actual usage. We note that at this time there are growing legal issues with using Google Analytics in Europe and we may have to reevaluate the tools we use.
Downloads
In addition to web statistics we also monitor downloads from our ftp sites. Our users typically download in excess of 750,000 Gb of data from UniProt each year - the equivalent of over 83,000 human proteomes every single day of the year! This data may be consumed directly by our users or incorporated into other resources, whose users consume UniProt data indirectly. We talk more about this ‘indirect’ usage of UniProt in the final section of the blog.
Citations
Citations of scientific literature are seen as a primary measure of impact within the sciences. Thus we often report the number of citations to the papers that we have written about UniProt such as our biennial papers in the Nucleic Acids Research Database Issues. But, how to choose our source of citations? Although in the past SCOPUS and ISI were our main sources, we, like most people, tend to use Google Scholar when reporting citations because it is freely available to all and due to its indexing strategy, tends to give the highest number of citations for any particular paper. Table 1 below shows the ten most cited papers describing UniProt. All were published in the annual Nucleic Acids Research Database Issue, which has played a key role in promoting the citation of data and knowledgebases in research - thank you! Taken together, these and other UniProt papers have amassed over 27,000 citations. This is a very large number, but even this does not represent the true impact of UniProt, as many users do not cite our papers. In the next section we delve into how to use full text articles to find this additional, uncited usage of UniProt.
Table 1. Citations of papers describing UniProt ordered by number of citations. All citation numbers are taken from Google Scholar in October 2021. Only the top ten citations are shown for the sake of brevity.
Using full text of articles
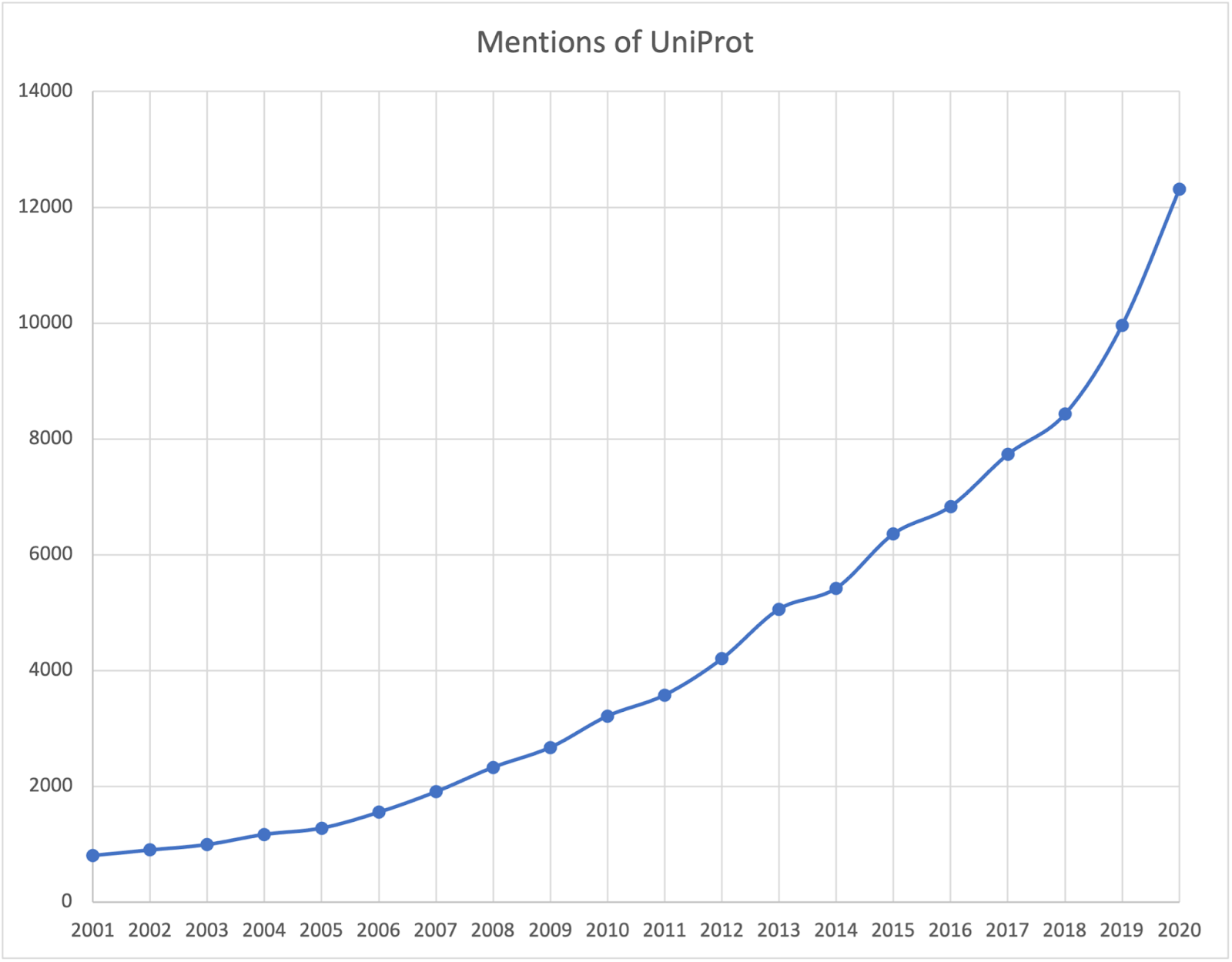
Figure 2. Graph showing the number of articles with mentions of UniProt or a synonym per year across the Europe PubmedCentral corpus.
The advanced search capabilities at Europe PMC allow us to search in specific sections of papers and identify where UniProt is mentioned (Figure 3). UniProt is most frequently mentioned in the Methods and Results sections of papers highlighting its key role in the design, execution, and interpretation of experiments. The pattern of UniProt mentions is similar to that for popular experimental techniques such as ‘proteomics’ and ‘CRISPR/Cas9’, although these tend to be mentioned more frequently in the ‘Introduction’ and ‘Discussion’ sections, perhaps as they are themselves the subject of much study and debate. Despite these small differences, UniProt is clearly a very important tool that research scientists mention in their publications.
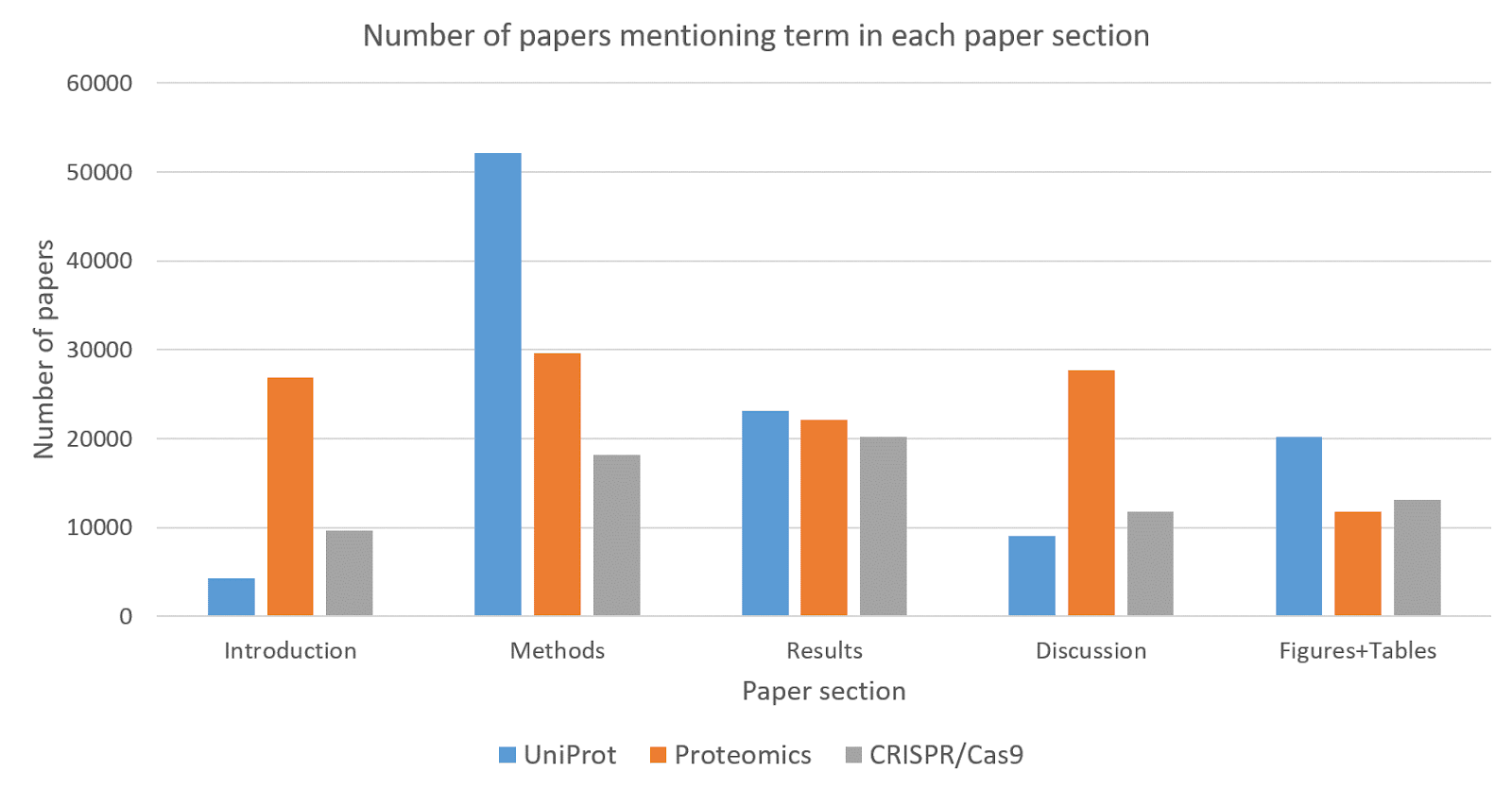
Figure 3. Graph showing the number of mentions of the search terms ‘UniProt’, ‘proteomics’, and ‘CRISPR/Cas9’ across sections of papers.
We also track the mentions of UniProt accession numbers (our stable identifiers for proteins) within the scientific literature. Europe PMC currently supports searches for identifiers from 46 molecular biology databases through its advanced search. In 2020 over 5,000 papers mentioned a UniProt accession number, which helps to connect the literature to not just UniProt, but also the 150 molecular biology data- and knowledgebases that UniProt cross links to. We strongly encourage researchers to cite UniProt accession numbers when publishing studies on proteins and their biology.
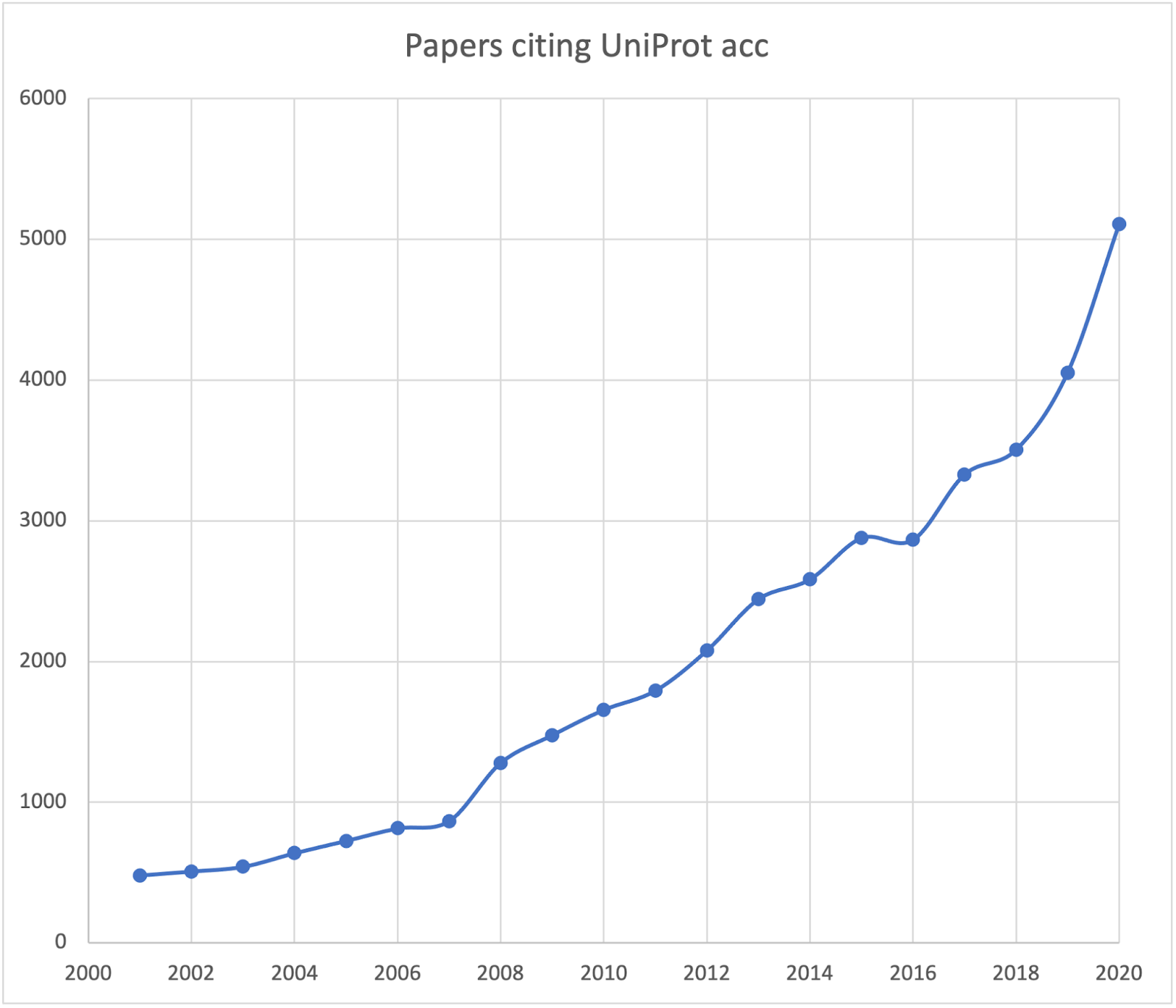
Figure 4. Mentions of UniProt accession numbers (stable identifiers) in the literature per year.
Acknowledgements of grant funding

Figure 5. Mentions of UniProt in papers acknowledging funding across NIH Institutes (left panel) and normalised to the mean fraction of UniProt mentions across all NIH funding acknowledgements (right panel), where the mean is set to 1.
VOSviewer and authorship networks
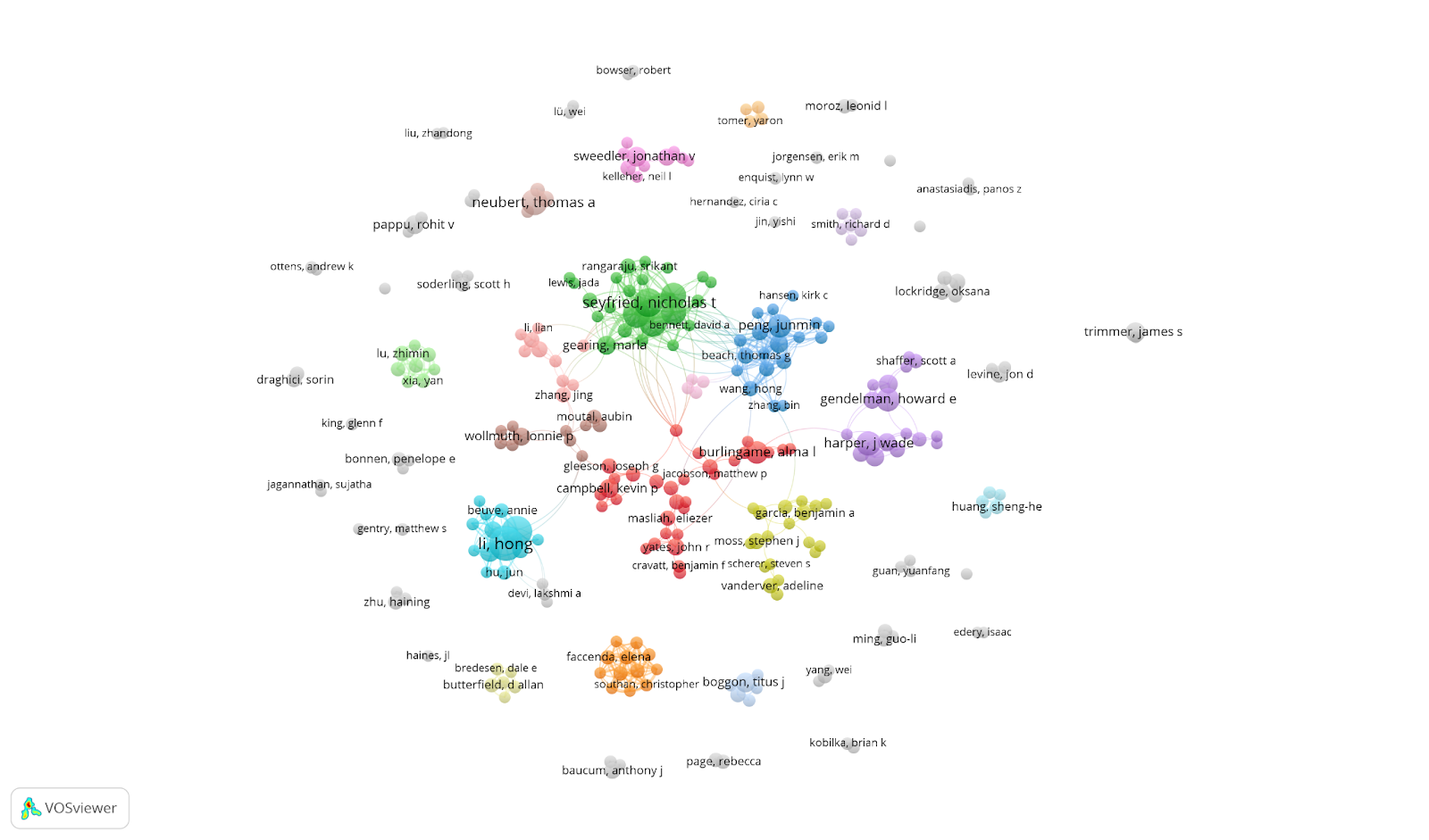
Figure 6. Co-authorship network of researchers who mention UniProt and acknowledge NINDS funding in their papers.
It is now much easier to investigate the research papers of the co-author clusters to get an understanding of how the NINDS funded community is using UniProt. For example, the large central green cluster comes from Nick Seyfried and colleague’s work on using proteomics, systems biology, and molecular biology to tackle fundamental questions related to the pathogenesis of Alzheimer’s Disease (AD) and other neurodegenerative disorders. They use UniProt as a source of protein sequences for their peptide identification pipeline. VOSviewer has a wide range of functionalities and we encourage you to explore them.
UniProt in patents
It can be quite difficult to understand how UniProt is used in industry, at least through literature based approaches, with far fewer academic papers published by our industrial colleagues. However, the patent literature gives us a window into the use of UniProt for biotechnology and biomedical applications. We have used the SureCHEMBL resource (https://www.surechembl.org/search/) to identify relevant patents. We can find more than 35,000 patents that mention UniProt or one of its synonyms.
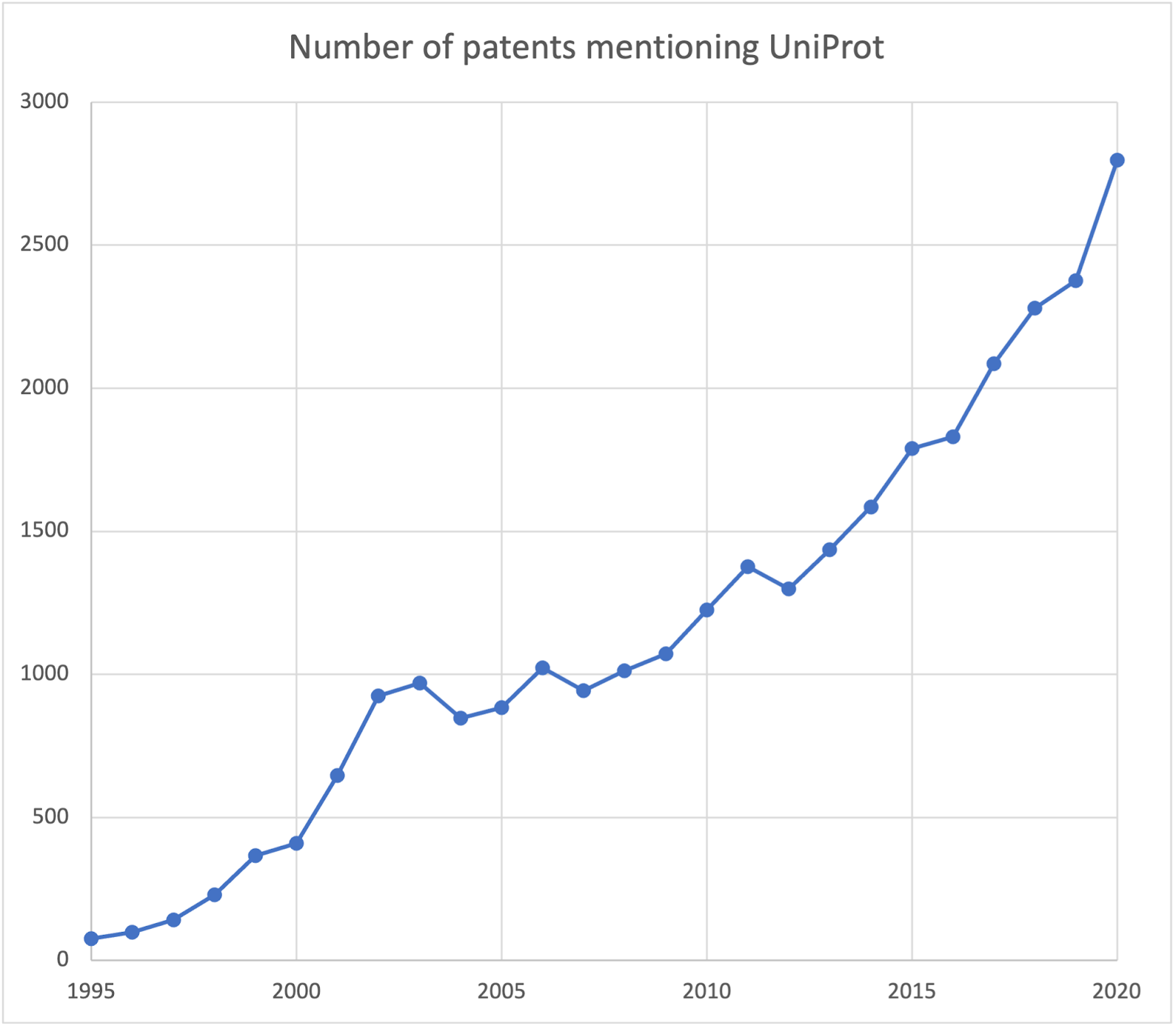
Figure 7. Graph showing growth of UniProt mentions across the patent literature per year.
Mentions of UniProt in the patent literature have been steadily increasing over time, with nearly 3,000 mentions per year in 2020. Patents mention specific proteins and cite UniProt accession numbers as a clear way to identify the specific materials of the patent.
Indirect usage of UniProt
Web analytics and citations of UniProt in literature and patents provide a good picture of the impact of a resource like UniProt, by measuring direct usage of UniProt data, as do downloads. However we know that UniProt data is also consumed indirectly too, by the user communities of many other resources and tools - like the Gene Ontology, Reactome, IMEx/IntAct, STRING, Ensembl, PDBe, InterPro, CATH, ChEMBL, Open Targets, and PHAROS, to name but a few. Each of these resources supports its own large and diverse user community, who also rely indirectly on UniProt data, sometimes perhaps without even realizing it. UniProt data is also used to train hundreds of computational tools to study and predict many aspects of protein biology, such as their functions (as in the Critical Assessment of Functional Annotation) and structures (like AlphaFold from DeepMind). Understanding the complex patterns of data use and reuse that are a feature of resource and tool development will be key to creating a more complete picture of the impact of a resource like UniProt, which, as we have seen in this blog, is considerable.
No comments:
Post a Comment